
Email:
juntongc[at]outlook.comGithub:
@jtchen2kX (Twitter):
@jtchen2kLinkedIn:
/in/juntongchenLocation:
Shanghai, China
Juntong Chen
/ 陈俊潼GPU Arch Engineer @ NVIDIA
I am currently a GPU Architecture Engineer, working on full-chip functional verification,
with a focus on the compute and memory subsystem
to support reliable and performant CUDA computing for next-gen NVIDIA GPUs.
I previously did research on scalable and ML-assisted data visualization @ ECNU and UCDavis
under the supervision of Prof. Chenhui Li and Prof. Dongyu Liu.
I like photography and music production in my spare time.
IEEE Conference on Visualization (VIS) 2025
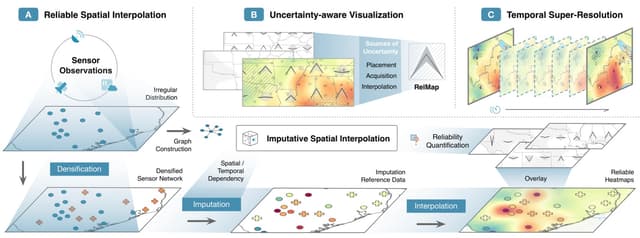
RelMap: Reliable Spatiotemporal Sensor Data Visualization via Imputative Spatial Interpolation
Improving the reliability of interpolation-based heatmaps using imputation data generated by GNNs and visually communicating various sources of uncertainty in the data.
IEEE Conference on Visualization (VIS) 2025
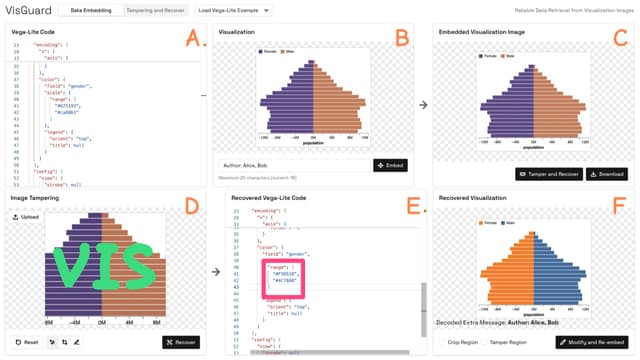
VisGuard: Securing Visualization Dissemination through Tamper-Resistant Data Retrieval
Embedding tamper-resistant data into visualization charts to safeguard visualization dissemination and information conveyance.


ACM SIGCHI Conference on Human Factors in Computing Systems 2024 (CHI 2024)
SalienTime: User-driven Selection of Salient Time Steps for Large-Scale Geospatial Data Visualization
Selecting a representative subset of time steps from temporal data with user-specified priorities, leveraging structural variation info learned by Autoencoders.

ACM SIGCHI Conference on Human Factors in Computing Systems 2024 (CHI 2024)
DoodleTunes: Interactive Visual Analysis of Music-Inspired Children Doodles with Automated Feature Annotation
Analyzing the interplay between music and children's artistic expressions by combining features from music and children's doodles, assisting in integrated education of music and visual arts.

IEEE Transactions on Visualization and Computer Graphics (TVCG), 2023
SenseMap: Urban Performance Visualization and Analytics via Semantic Textual Similarity
Quantifying and visualizing various urban performance measures using Points of Interest (POIs) data and textual contexts as the semantic representation of urban functions.


IEEE Transactions on Visualization and Computer Graphics (TVCG), 2022
GraphDecoder: Recovering Diverse Network Graphs from Visualization Images via Attention-Aware Learning